I never really got into log shipping. I didn’t have to. I was lucky enough to deal with only one instance of SQL Server early in my career, and then I moved almost instantly into Microsoft where I worked exclusively on Failover Cluster instances. After a couple years, we finally moved into using Availability Groups with Database Mirroring. Still, never had to deal with anything below that.
Our migrations were fairly straightforward. Stop all services, set all databases to read-only, take a backup, restore to the new server, set to read-write, and move the DNS name to point to the new cluster. Easy as pie, even when there were dozens of databases.
However, migration is not as easy when you are talking terabytes of data. Which is the case when I began migrating our System Center Operations Manager (SCOM) main database and data warehouse. Suddenly, I’m having to deal with 3 TB of data. That is not so easy to deal with.
A couple months before, the first version of sp_AllNightLog had been announced. I hadn’t paid much attention to it, because it didn’t fulfill a need of mine. Now, suddenly, maybe it could. I decided to give it a try.
I already had Ola Hallengren’s maintenance scripts running backups on the source server, so I didn’t see the need to install sp_AllNightLog there. I was setting up a new availability group, so I installed it on both of my target servers. From now on, I will talk only about one server, but everything I show, and did, applied to both servers. I ran the following code to set it up:
EXECUTE sp_AllNightLog_Setup @RPOSeconds = 900, @RTOSeconds = 900, @BackupPath = ‘S:\Databases’, @RestorePath = ‘\\SourceServer\Backups\SOURCESERVER’, @Jobs = 2, @RunSetup = 1;
This generated six SQL Agent Jobs, two backup jobs, two restore jobs and two polling jobs.
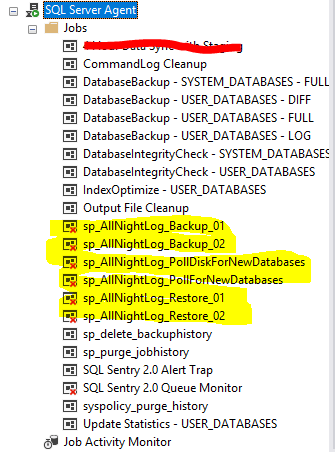
I enabled the sp_AllNightLog_PollDiskForNewDatabases job, the two restore jobs, and then went to look at the source code to see which tables were being populated. It turns out restore information actually go into the msdb.dbo.restore_worker table, while backups go to an msdbCentral database that is created as part of the setup sproc. So I took a gander in there.

Uh oh. We have system databases in there. What the heck?? I took a look at the job history of the two restore jobs. For some reason, nothing was in the history. Even more what the heck??
Digging around in the source code for sp_AllNightLog, I found out a couple interesting things.
First, there was no filtering based on existing databases. This meant that the version of msdbCentral would get overwritten. I’m not so sure about that. Maybe that needs to be filtered on? I discovered later (documentation ftw) that this was by design. msdbCentral holds the backup information and they wanted to have that information available on the currently valid node to make sure they were meeting RTO/RPO metrics.
Secondly, there was no filtering on system database. I stopped the restore jobs, put into the steps to push out to a log file, and then restarted them. Ahah! It was attempting to restore system databases, but thankfully failing. Not good at all.
Thirdly, the restore agent job didn’t run and return. It looped continuously. This meant I wouldn’t see the output unless the job was stopped. Not good.
I undertook two things immediately. I added a line to the sp_AllNightLog that filtered out system databases (and created an issue on Github to track this bug). Then I added output to a file logging for the agent jobs. Now I could finally see what was going on.
Lo and behold, it worked! I could leave it be for days at a time and it would keep everything up to date automatically. If I needed to reseed the database, I would disable the polling and restore agent jobs, truncate the msdb.dbo.restore_worker table, delete the existing databases, and then enable the polling and restore agent jobs. It just worked!!
As a way to help me monitor what was going on, I also created a set of monitoring queries that I have posted here. They show various configuration options, including what databases will be restored, and which ones will be backed up.
I want to highlight just the last line.
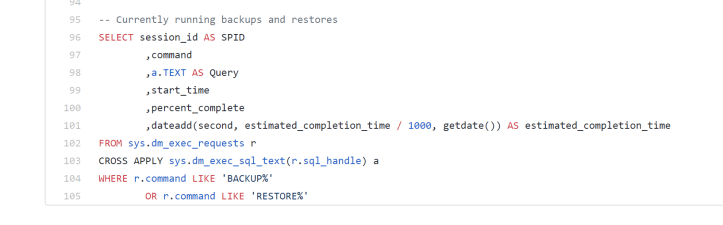
This query allows you to see, in real time, what restore and backup operations are happening right at this second. It is invaluable to see how far along, with an actual percentage value, those jobs are. It helps when you are restoring multi-terabyte databases and log files.
I used it to initially seed both nodes in the AG. However, when it came time to switch over, I needed to drop all the databases on the secondary node due to issues with the AG itself. Going forward, I would only do the initial seeding to one node. Then I would cut over to that node, making it primary, and using sp_AllNightLog to seed any secondary nodes before joining the databases to the AG. This is what I eventually did with my current setup. Cutover was smooth, and joining the AG was seamless. Just make sure to disable the agent jobs before joining a node to the AG.
Thanks go out to Brent and the team at Brent Ozar Unlimited for some awesome tools.

Glad we could help, sir! About not filtering msdbCentral during the restore process – that’s by design. We wanted to be able to bring our msdbCentral around from server to server as we failed over in log shipping because we store the backup history in there, and report on it to see whether we’re meeting our RPO/RTO.
After further reading, I did discover that. I will have to document it in the blog post. In retrospect, it seems like a great design decision. Up front, it was not clear why it wasn’t being filtered. Score one for RTFM.